Basic Blocks and Traces:基本块、迹¶
约 1089 个字 4 行代码 6 张图片 预计阅读时间 4 分钟
这一阶段的目标是将 IR 转换为更加契合机器码的 IR。上一章节讲到的 IR 与机器码之间有一些 mismatch:
- CJUMP 可以跳到两个 label,而机器码当 false 的时候只能进入下一条指令。
- 表达式内的 ESEQ 节点实现起来不方便
- stmt 是有副作用的
- 不同的 subtree 顺序可能会引发不同的副作用
- 表达式内的 CALL 节点也有同样的问题
- CALL 内部的参数如果也是 CALL 的话,可能会导致参数顺序不一致
解决方法是:
- 将 IR 树转换为 canonical trees
- 消除 ESEQ 和 CALL 的相关 mismatch
- 将上一部得到的 list 分组为 basic blocks
- 将 bb 排序成 traces 的集合,使得每个 CJMUP 的后面都紧跟着 false label
- 消除 CJUMP 的相关 mismatch
1. Canonical Trees:规范树¶
1.1 定义¶
规范树是:
- 没有 SEQ 和 ESEQ 节点
- 每个规范树最多有一个 stmt 节点,也就是根节点。剩下的全是 exp 节点
- 每个 CALL 节点的父亲要么是 EXP(...),要么是 MOVE(TEMP t, ...) 的形式
- CALL 节点的儿子不能是 CALL 节点
两个概念和在一起:
- CALL 节点的父亲必须是规范树的根节点
- 一个规范树最多一个 CALL 节点,因为 EXP(...) 和 MOVE(TEMP t, ...) 都只能有一个儿子
1.2 转换操作 1:消除 ESEQ¶
思想是上提 ESEQ 节点,直到其能变成 SEQ 节点的形式。
例子
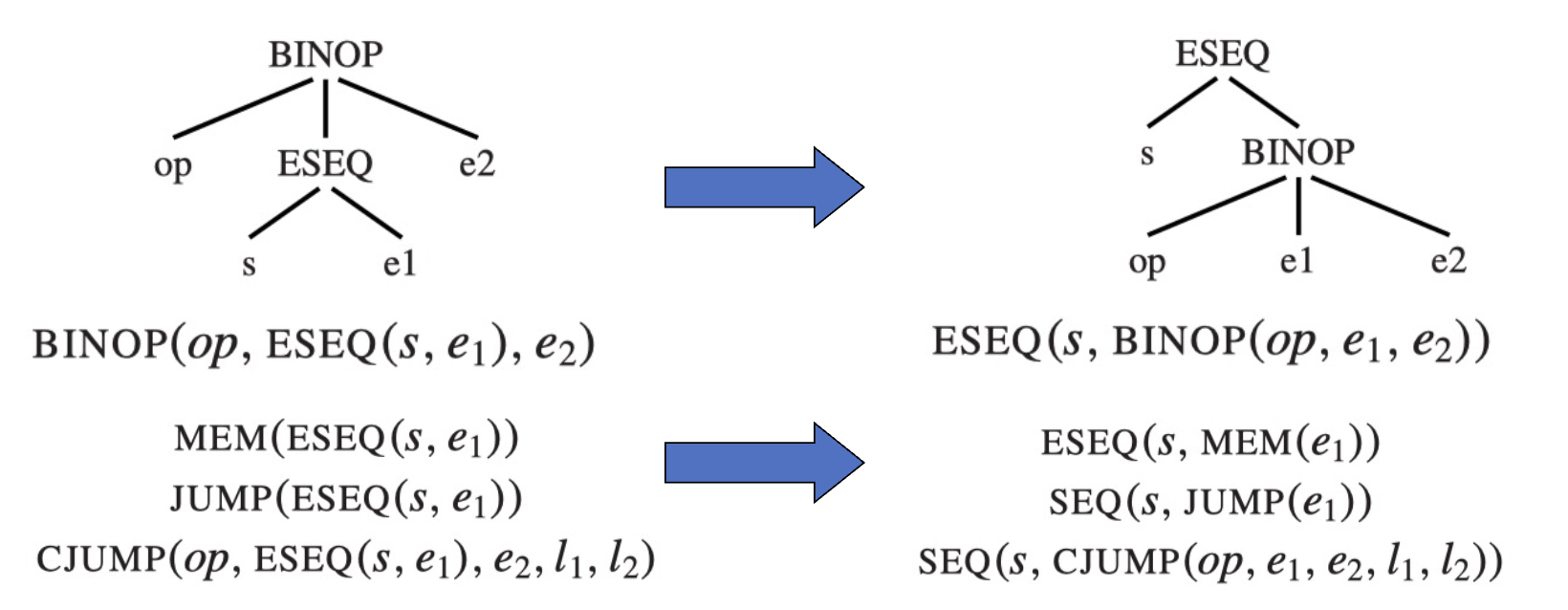
需要注意以下特殊情况:
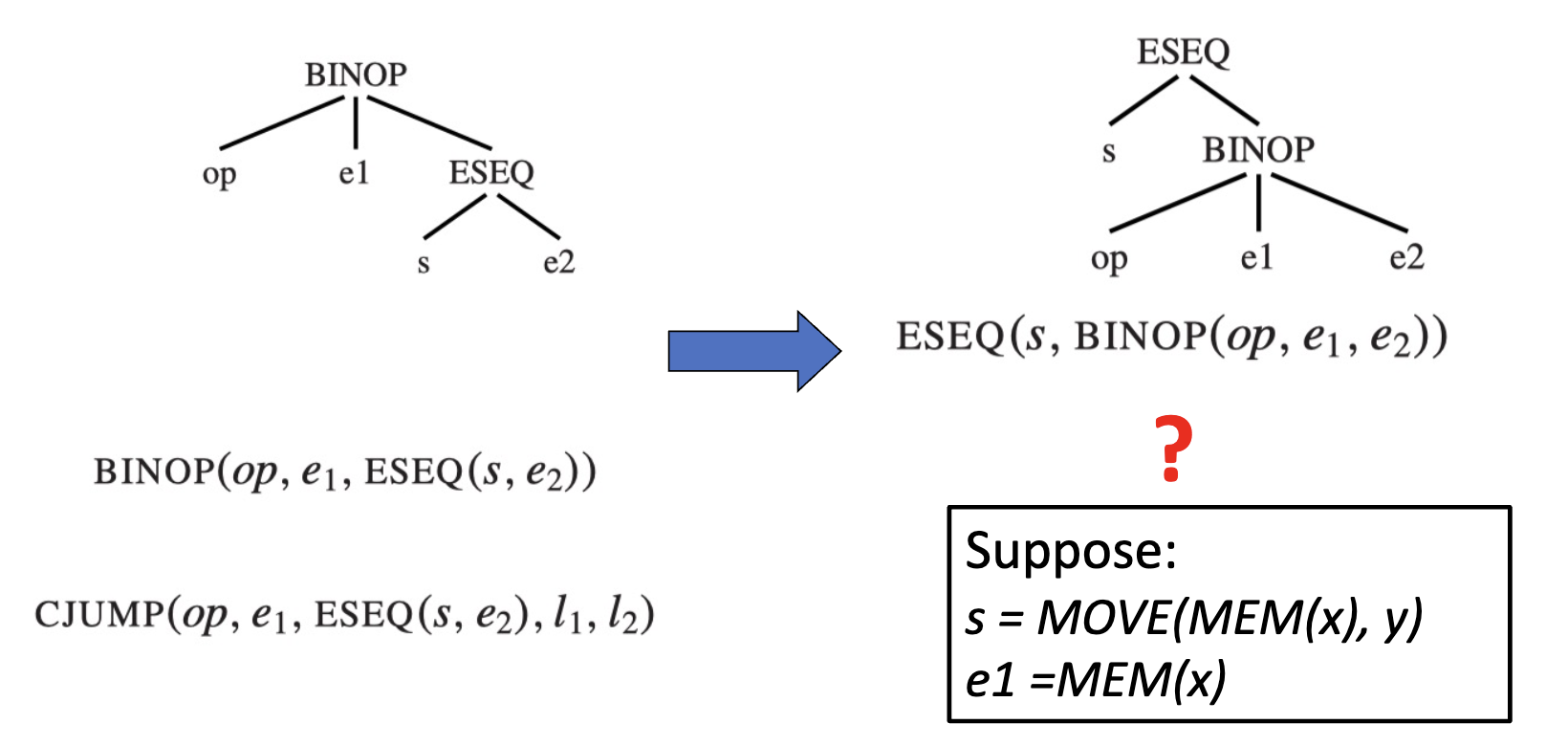
为了维持语句执行的顺序,e1 需要在 s 执行之前就获取到表达式的值。方法是:
- 将 e1 的值存储到一个临时变量 t 中
- 将 t 作为 e1 的值返回
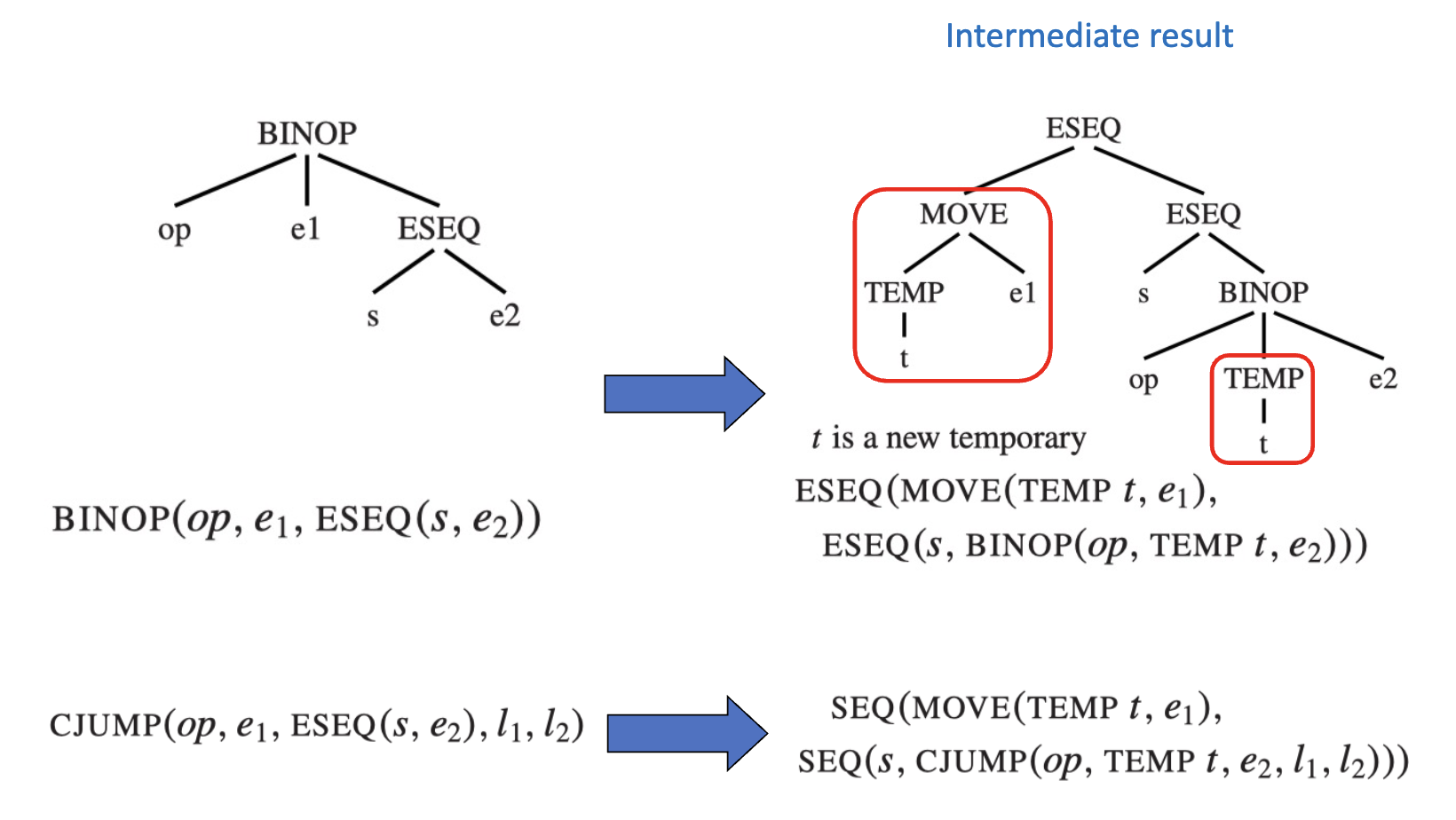
但是也不全是这样,如果 s 和 e1 可以交换(commute),那么就可以直接将 e1 上提到 s 的前面。
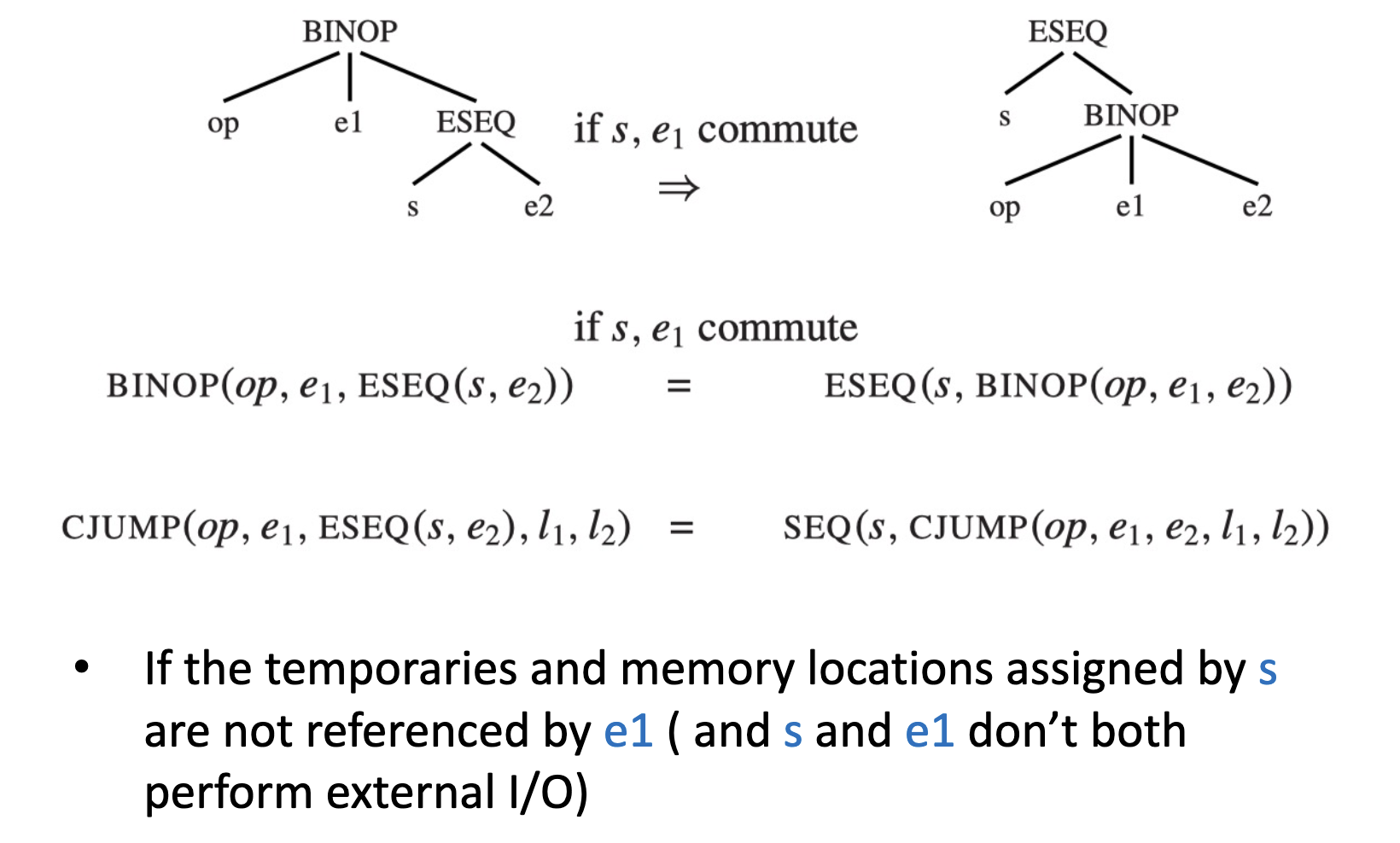
如何知道是否 commute?
事实上,有些时候是否 commute,不是编译时刻就能够确定的。所以我们保守的估计:只有确定 e1 和 s 是 commute 的时候,才按照 commute 的方式上提,否则都按照上面的方法处理。
1.3 转换操作 2:将 CALL 移动到顶部¶
许多架构的 CALL 返回值都写在一个固定的寄存器中,这时如果有嵌套的 CALL,就会导致返回值覆盖丢失。为了避免这种情况,我们的想法是:每个返回值都赋给一个全新的临时寄存器。
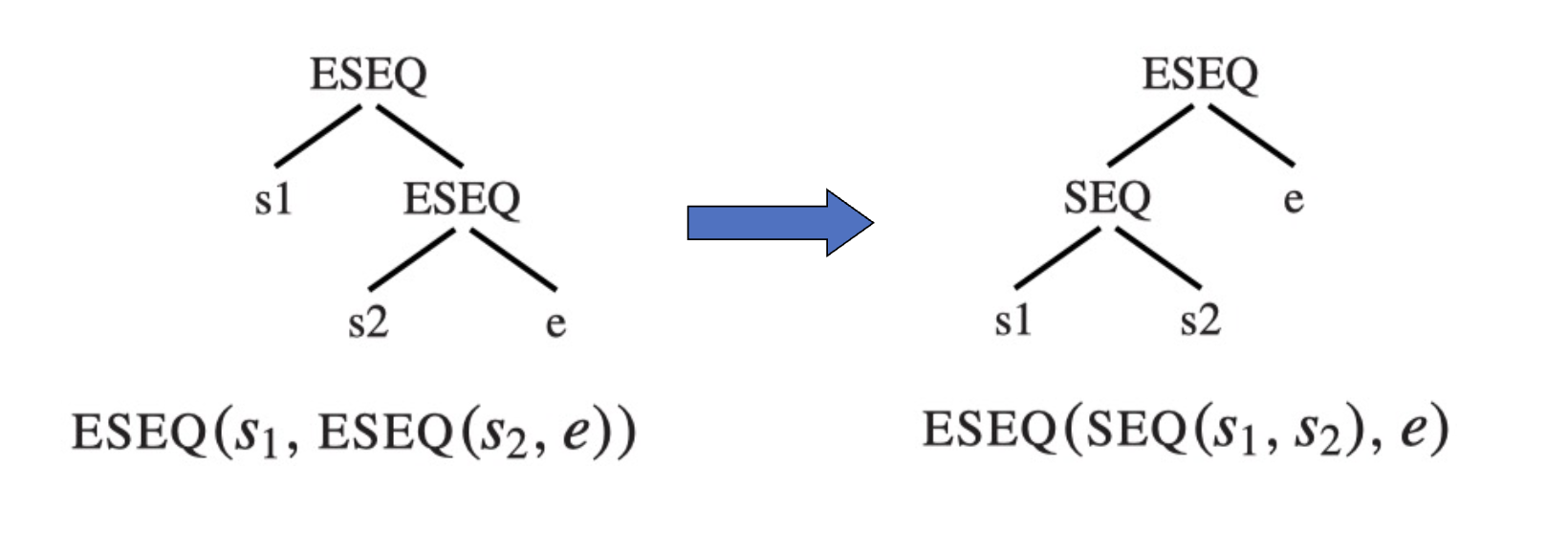
1.4 转换操作 3:消除 SEQ¶
很简单。前面的工作完成后,树长得像
持续应用规则 SEQ(SEQ(a, b), c) -> SEQ(a, SEQ(b, c)),直到树长得像
这样,就可以直接把这个树拆成语句 s1, s2, ..., sn。
2. Basic Blocks:基本块¶
2.1 定义¶
基本块是一个语句序列,总在开始进入,结尾退出,也即:
- 第一个语句是一个 label
- 最后一个语句是一个 JUMP 或 CJUMP
- 中间没有其他的 labels 和 JUMP/CJUMP
2.2 转换操作¶
很直观,就是对程序段进行线性扫描:
- 发现一个 label,就意味着一个新的基本块的开始
- 发现一个 JUMP 或 CJUMP,就意味着一个基本块的结束
- 然后在基本块的前后加上可能需要的 label 或是 JUMP
3. Traces:迹¶
BB 可以按照任意顺序重排,最后的执行结果是一样的。
- 基于此,可以重排使得 CJUMP 的 false label 紧跟在 CJUMP 后面
- 还可以让许多无条件 JUMP 后面紧跟着目标地址,这样就可以删掉这个 JUMP
Trace(迹)就是一个有序的基本块集合。一个程序有很多个,可能互相重叠的 trace。
基于上面的目标,我们希望组织出这样的 traces:
- 每个 block 仅存在于一个 trace 中
- 每个 trace 是 loop-free 的,也即没有循环
同时我们需要尽可能减小 trace 的数量。
算法就是 DFS:

为了简化后续的流程,Tiger 编译器还会做一些调整:
- 任何后面紧跟着 false label 的 CJUMP
- 不动
- 任何后面紧跟着 true label 的 CJUMP
- 调换条件
- 其他情况(CJUMP 后面紧跟着的不是 true label 或 false label)
- 创建一个新的 false label,跳转到这个 label
- 之后,再跳转到真正的 false label