Translate to Intermediate Code:中间代码生成¶
约 1021 个字 1 张图片 预计阅读时间 3 分钟
1. 引入与定义¶
为什么需要 IR?为什么不直接把 AST 翻译为机器码?
- 模块化设计
- N 种源语言,M 种目标机器
- 如果直接翻译,需要 N * M 个翻译器
- 如果有中间代码,只需要 N + M 个翻译器
- 可移植性
IR 是一种抽象化的机器语言:
- 能够在不携带太多机器语言实现细节的情况下,表达目标机器的操作
- 和源语言的细节无关
不同的编译器可能会使用不同的 IR,例如 Tiger 编译器使用的是表达式树,还有用三地址码的等等。一个编译器可能会用多级 IR。
IR 把编译器分成前后端
- 前端
- 词法分析
- 语法分析
- 语义分析
- 翻译为 IR
- 后端
- 优化 IR
- 翻译为目标机器代码
2. 三地址码 Three-Address Code¶
这是一种中间代码的形式,最常见的 basic instruction 是:x = y op z。
- 一条指令最多有四个域:一个操作,三个地址
- 地址可以是
- name:一个源程序名字
- constant:一个常量
- compiler-generated temporary:编译器生成的临时变量,例如 t1
- 指令的右边最多有一个 operation,因此源程序的一句话可能要分成多条指令。
- 有的时候为了适应不同的语句,可能需要做三地址码的变体,例如
t2 = -t1 - 因此,三地址码没有严格的标准格式
- 常见的把三地址码组织起来的形式有数组和链表,由于最多有四个 field,可以实现为 quadruples。如果没有四个 field,空的地方可以用 null 填充。
3. 中间表示树¶
中间表示树是由一个一个 IR 节点拼接起来的,节点总体分为两类:表达式类型与语句类型。
- 表达式类型
- CONST(i):常量 i
- NAME(n):标签 n
- TEMP(t):临时变量 t,这里是虚拟寄存器
- BINOP(op, e1, e2):二元操作符,左边和右边都是表达式。操作包括:PLUS, MINUS, MUL, DIV, AND, OR, XOR, LSHIFT, RSHIFT, ARSHIFT
- MEM(e):内存地址 e 开始一个 word 大小的数据。MEM 在 MOVE 的左边时候代表 store,否则代表 fetch
- CALL(f, l):用参数列表 l 来调用函数 f。从左到右传递参数
- ESEQ(s, e):表达式 e 的值是 s 语句执行后的结果。s 是一个语句,e 是一个表达式。ESEQ 可以用来实现副作用,例如函数调用。
- 语句类型
- MOVE(TEMP t, e):把表达式 e 的值存储到临时变量 t 中
- MOVE(MEM(e1), e2):把表达式 e2 的值存储到内存地址 e1 中
- EXP(e):表达式 e 的值被计算出来,但不存储到任何地方(discard)
- JUMP(e, labs):跳转到位置 e 的标签 label
- CJUMP(op, e1, e2, t, f):计算表达式 e1 和 e2 的值,比较它们的值,如果满足条件 op,则跳转到标签 t,否则跳转到标签 f。
- SEQ(s1, s2):执行语句 s1 然后执行 s2
- LABEL(l):定义一个标签 l。NAME(l) 可以用来引用这个标签。
4. 中间表示树的翻译¶
4.1 表达式¶
AST 中的表达式翻译成 IR,有三种形式:
- 带有返回值的 T_exp
- 不带有返回值的 T_stm
- 带有布尔值的 conditional jump
例如:
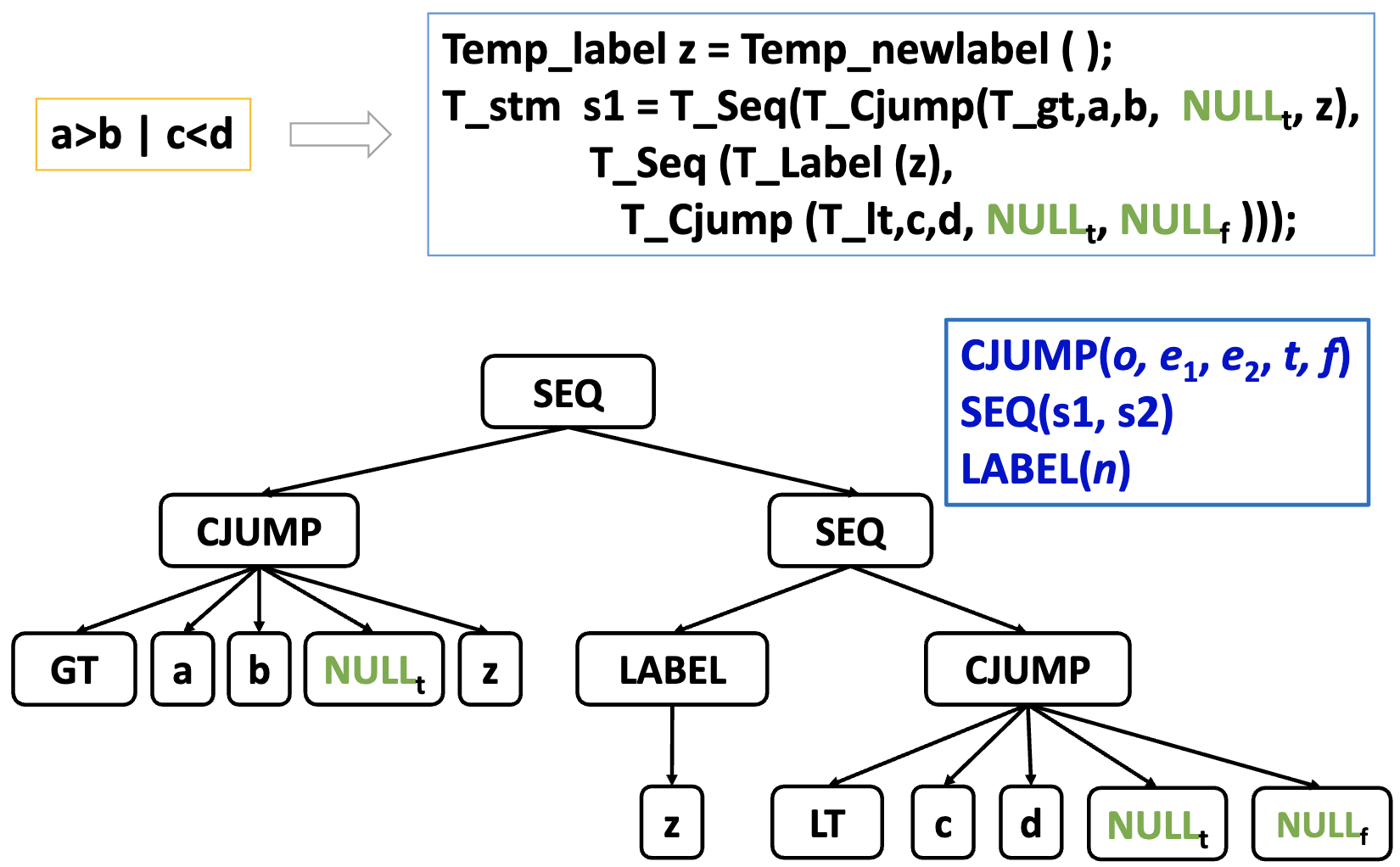
注意这里我们还不知道 true-destination 和 false-destination 是什么,所以填上 NULL。后续知道了之后再填上。这个叫做 backpatching,其中有 true patch list 和 false patch list。
4.2 简单变量¶
获取栈帧中存储的一个变量,可以使用 MEM(BINOP(PLUS, TEMP fp, CONST k)),其中 k 是变量在栈帧中的偏移量。
这里也可以做一个结合的简写,记为 MEM(+(TEMP fp, CONST k))。
4.3 函数调用¶
要记得把 static link 传递给函数调用。CALL(NAME lf, [sl, e1, e2, …, en])
4.4 变量声明¶
需要在栈帧中预留好空间(FP + offset)
4.5 函数声明/定义¶
在函数体前面和后面加上 prologue 和 epilogue。