Activation Records:活动记录¶
约 2124 个字 7 行代码 4 张图片 预计阅读时间 7 分钟
函数调用的时候,会在内存中生成一个函数的“活动”(activation),每调用一次函数就会生成这样的实例,其中有函数的局部变量等信息。
函数调用之间是一种 LIFO 的行为,因此这种行为可以使用栈来实现。这个栈的一个单位叫做 activation record(活动记录),也叫做栈帧(stack frame)。每个函数调用都会在栈上分配一个新的活动记录。
1. 栈帧的定义¶
典型的栈包括 push 和 pop 操作,但是对于栈帧来说,每一片段内存都包含了函数调用的所有信息,因此栈帧的结构会更复杂一些。我们可以把这个栈看作一个巨大的数组,其中需要一些标志位来标记栈的状态。
- Stack Pointer(SP):一个特殊的寄存器,指向栈顶。
- 一般认为 sp 上方的内存区域都是垃圾;sp 下方的区域都是需要分配的内存。
进入函数的时候,stack 会增长,增长的内容足以放下函数需要的局部变量、参数等信息。函数调用结束后,栈会缩小,释放掉这些内存。一个函数的栈帧就是这片区域。
一般来说 run-time stack 从高地址到低地址增长。栈帧是连接 caller 和 callee 的桥梁。因此设计好栈帧的结构能够让函数调用更高效。
2. 栈帧的结构¶
下图是一个典型的栈帧结构:
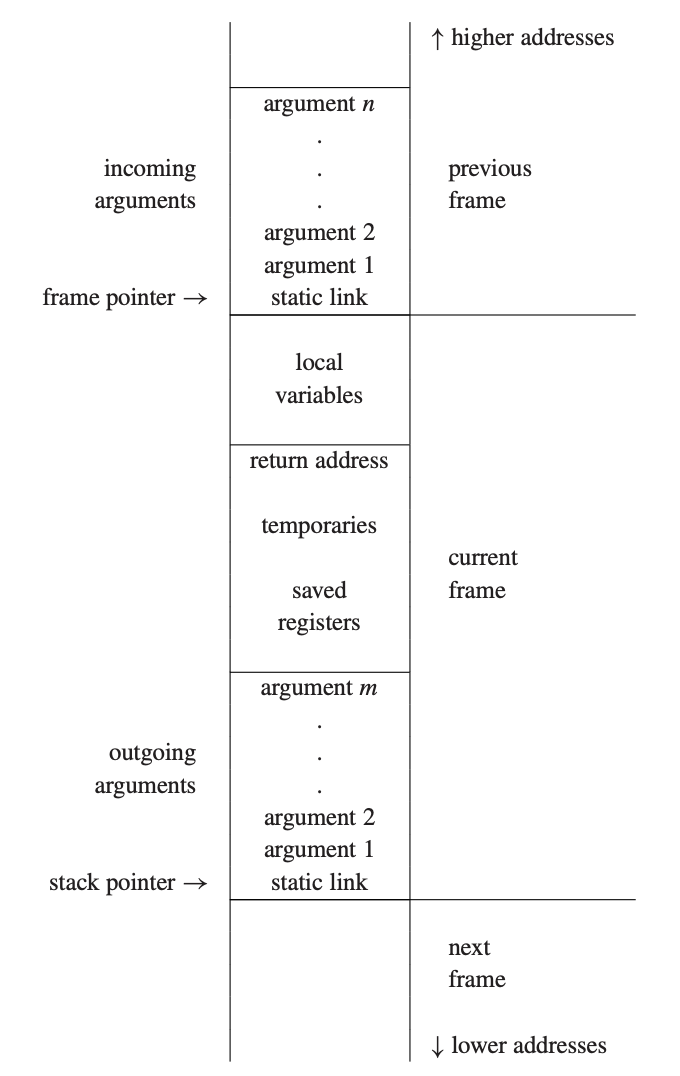
这里面包含:
- incoming arguments:caller 传入的参数。
- local variables:函数内部的局部变量。有些是保存在这个栈帧中的,有些是保存在寄存器中的。
- return address:函数调用结束后,返回到 caller 的地址。这个地址是 CALL 指令创建的。
- temporary values:临时变量,可能是函数调用的中间结果。
- saved registers:保存一些寄存器以便其他用途使用。
- outgoing arguments:callee 传给其他函数的参数。
- static link:一会儿会讲到。
2.1 帧指针 FP¶
注意到这里除了 sp 之外还有一个指针:
- Frame Pointer (FP):指向当前栈帧的起始位置,实际上是上一个栈帧的栈顶。
每当进入一个函数调用的时候:
- 旧的 FP 会被保存到栈中。
- FP = SP
- SP = SP - size_of_new_frame
当函数调用结束的时候:
- SP = FP
- FP = old_FP
2.2 寄存器¶
栈帧中还保存有寄存器的值,分为:
- Caller-saved registers:调用者需要保存的寄存器。函数调用前,调用者需要保存这些寄存器的值,以便函数调用结束后能够恢复。
- Callee-saved registers:被调用者需要保存的寄存器。函数调用前,被调用者需要保存这些寄存器的值,以便函数调用结束后能够恢复。例如存储旧的 FP 的寄存器。
2.3 调用参数¶
Tiger 语言的调用采用的是值传递(Pass-by-Value),即函数调用时将参数的值复制到栈帧中。对函数内部的形参的修改不会影响到实参。
如果所有的参数都用 stack 来传递,可能会导致不必要的 memory traffic,为此,需要制定调用规约(calling convention),即规定哪些参数放在栈中,哪些参数放在寄存器中。
在 Tiger 语言中,前几个参数会放在寄存器中,剩下的参数会放在栈中。这样可以减少内存访问,提高函数调用的效率。
一些其他的传参优化
假设有这样一段程序:
假设函数 f 从寄存器 r1 传入参数 a,并且 f 调用 h 的时候,也需要将参数放在寄存器 r1 中。正常情况下,应该先将 a 的值保存,然后再将 z 的值放入寄存器 r1,然后调用 h。
但是如果有以下特殊情况:
- 如果当
h(z)被调用的时候,a是 dead variable,也就是a在h调用之后不会被使用,那么可以直接将z的值放入寄存器r1,而不需要保存a的值。 - 如果当前函数时 leaf procedure,则不需要将其 incoming arguments 保存到栈中,而是直接将参数放在寄存器中。因为 leaf procedure 不会调用其他函数,所以不需要保存参数的值。
- 有些带有优化的编译器会使用 inter-procedural register allocation(跨过程寄存器分配)来优化函数调用的参数传递。这样可以减少内存访问,提高函数调用的效率。
- 有些架构有 register windows(寄存器窗口),可以在函数调用时直接使用寄存器来传递参数,而不需要使用栈。这种方式可以减少内存访问,提高函数调用的效率。
2.4 返回地址¶
- 如果在地址 a 处调用了一个函数,那么通常情况下,返回地址就是 a 的下一条指令的地址。
- 现代的机器中,call 指令一般会自动将返回地址放进一个指定的寄存器中,例如 RISC-V 的
ra寄存器。 - 对于一个 non-leaf procedure(非叶子过程),返回地址会被保存在栈帧中,以便在函数调用结束后能够恢复。(除非使用了 inter-procedural register allocation)
- 对于一个 leaf procedure(叶子过程),返回地址可以直接使用寄存器中的值,而不需要保存到栈帧中。
2.5 栈帧内变量¶
一般情况下,调用规约都会把函数参数、返回地址、返回值都存在寄存器中。那么什么时候把值存在内存(栈帧)中呢?
- 以引用形式传递的变量(必须包含内存地址),例如 C 语言的指针。
- 某个变量被 procedure 内部嵌套的 procedure 使用。
- 变量值太大,放不下一个单独的寄存器中。
- 变量是数组,为了获取分量必须要有地址的计算。
- 某个寄存器另有他用,不能随便使用。
- 局部变量、临时变量数量太多,不能全部放入寄存器中,只能 spill 一部分进入栈帧。
Varible Escape
说一个变量逃逸,如果:
- 变量是通过引用来传递
- 变量的地址被取到
- 或者说变量被嵌套函数使用
例如 Pascal 语言的 pas-by-reference 传递方式。
总结一下:

2.6 静态链接 Static Link¶
在允许嵌套函数的语言中,内层函数有时要使用外层函数声明的变量。我们可以通过 FP 来获取局部变量。
- 即使 FP 的真实值只能在运行时知道,但是每个局部变量相对于 FP 的 offset 是在编译时刻可以知道的。
那么一个嵌套的函数如何来获取到一个 “non-local” 的变量呢?这就需要使用静态链接(static link)。
- 当函数 f 被调用的时候,其会被传入一个指针,指向最直接包裹函数 f 的函数(假设是函数 g)的栈帧的起始位置。这个指针就叫做静态链接(static link)。
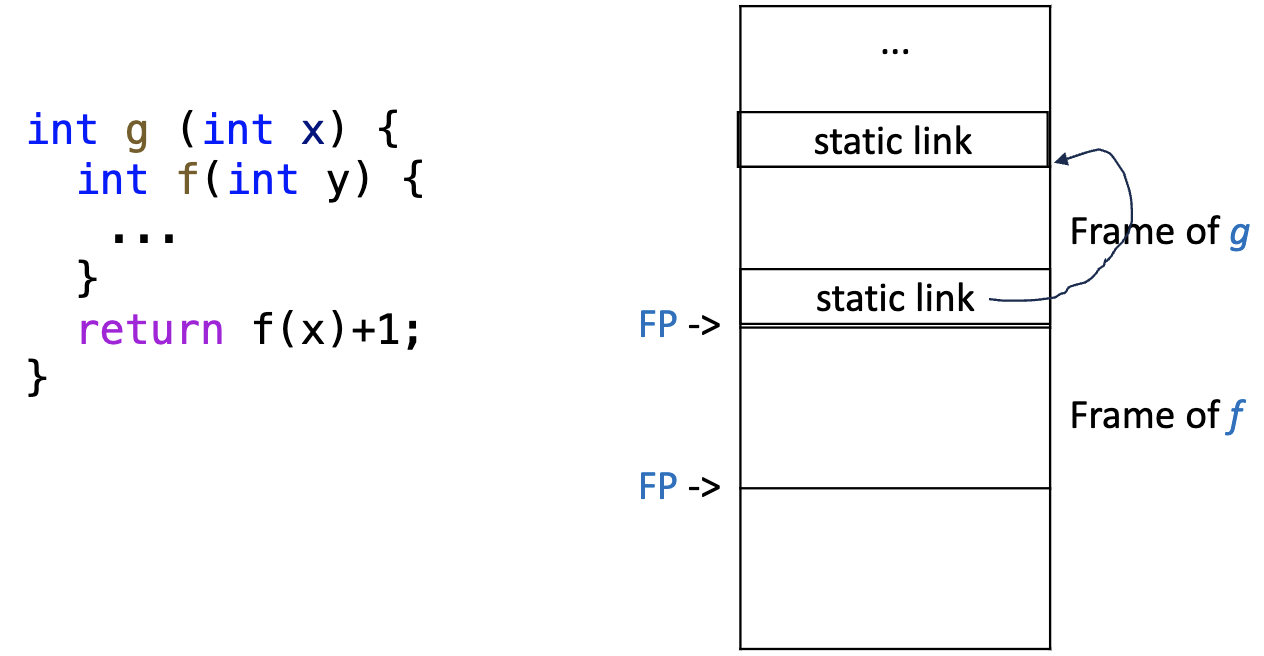
内层函数获取外部的变量的过程就是从自己的 static link 开始到上一层的栈帧,如果上一层栈帧有需要的变量,就直接使用;如果没有,就获取到上一层的 static link,继续向上查找,直到找到需要的变量或者到达栈顶。
- 每个函数都绑定了一个嵌套深度
- 当嵌套深度为 n 的函数要获取在嵌套深度为 m 定义的变量,需要向上爬 n-m 层栈帧。
- 优点:参数传递的时候,overhead 很小
- 缺点:参数获取的时候,要一步一步往上爬
- 里面有较多的 indirect references
- 函数嵌套深度可能会很深,导致访问效率低下
其他实现 Block Structure 的方式
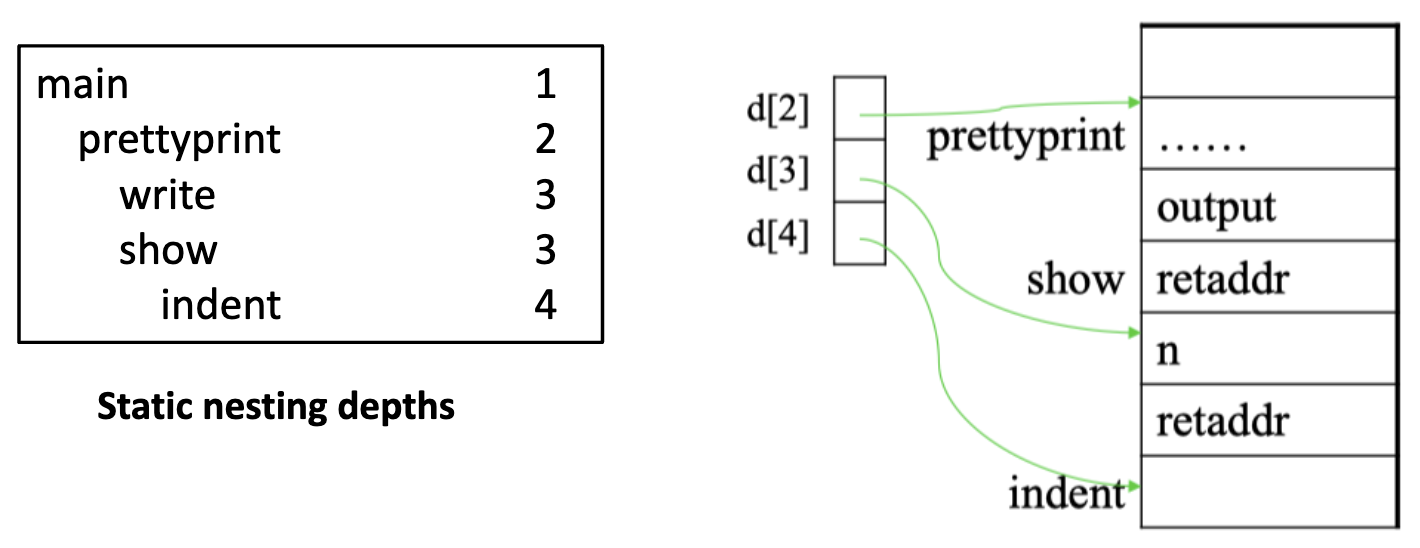
除了使用静态链接,还可以使用 display(显示链接)来实现 Block Structure。
- 每个函数都有静态的嵌套深度
- 有一个 display 数组,记录最近进入的、嵌套深度为 i 的函数的栈帧的 FP。
还有一种方法,叫做 lambda shifting,当 g 调用 f 的时候,g 中所有要被 f 或是 f 内部的嵌套函数使用的变量都会传递给 f 作为额外参数。这样的翻译过程要从内层函数开始,逐层向外翻译。